Building an AWS Serverless system — conveniently
This is the first in a series of blog posts about how to build an API-based serverless service in AWS. We want to build a professional, always-online real-world application that is easy to develop, monitor, test, and maintain. The idea is to go away from simple snippets widely available online and focus on the ways-of-working side of things, to offer a developer a fun working experience and have a fully secure system.
Building a basic API-fronted serverless database REST-service is very well described online, for example in this AWS tutorial. In this blog I would like to focus on the convenience of working with a project in an enterprise environment. A good system would have a modular, extendable design, has proper testing and deployment CI/CD automation, easy to monitor and detect problems. I am a big fan of no-nonsense design approaches that allow me to use my time on creating business logic and have little routine overhead. So we keep things lightweight where possible and utilize as much as possible managed services offered by GitHub and AWS.
The system should be easy to work with in every aspect. If writing tests is difficult, for instance, the work will be pushed away and procrastinated. Just to be honest: it is sometimes psychologically hard to see "real value" in testing and "new features" sometimes take all the spotlight on the assorted planning meetings. An imaginary "lack of value" plus difficulty to write a good amount of tests is a recipe for disaster: systems with a low test coverage do not usually behave well, create massive negative feedback, and ruin the reputations of everyone involved, not to mention financial drawbacks. In this example, if we make testing convenient and fast to implement, these will not become an obstacle and the convenience pays off by having a better system. In my following blog post, I talk about testing, but I like to stress how convenience, in general, is important.
A disclaimer - what I describe here is one way to do things that come from my personal experience. It is not meant to be a rigid, set-in-stone recipe, but rather something you would, with a critical attitude, adapt to your case.
Architecture
Here is a typical reference architecture that I employ - it is a quite common situation where CloudFront and S3 are serving static content and API Gateway + Lambda hangle business logic and interact with a database hidden in a private VPC subnet.
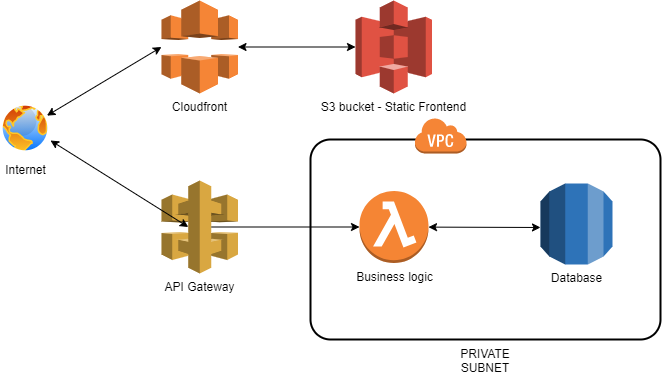
If you try to do it vanilla way, then you got to code many small resources such as copious Security Groups for every bit or, for instance, deploying Glue or Lambda sources to S3. To cut the mundane parts, we heavily rely on serverless.tf library of Terraform modules, which greatly simplifies the creation of complex configurations.
Environments and AWS accounts
In professional software development, a system usually exists in several copies, or Environments, and interacts with some external systems, which I call Dependencies. The Environment is essentially a set of resources that work together. For instance, preproduction environment resources connect to beta-test endpoints of your Dependencies, and production to the actual Production ones.
How these environments should map to the AWS accounts? When we have several environments, having separate AWS account for each might become unmanageable; furthermore, in some companies creating new accounts might be severely slowed down by the IT department's scrutiny. Therefore, we usually design our infrastructure to permit a co-existence of several environments in the same AWS account, namely using the following rules:
- Every AWS resource created by our project is named after the Environment and Terraform workspace (see below) it belongs to. Therefore, there are no resources that are used by two or more environments within our project (however Dependences, such as manually created secrets and third-party services, are sometimes end up shared).
- In addition to your resources being fully independent between Environments, we do our best to request also different Dependences for different Environments, to minimize crosstalk, confusion, and maintenance challenges. If the same Dependency is shared between two Environments and its data can be modified by either, it may cause annoying inconsistencies in data; however, I should say in practice such full isolation is not always achievable. Upstream Dependencies (such as raw data input for your processing) that we only read from are less dangerous to be shared.
- We might have a zoo of testing Environments under the same "roof", but the production environment, however, should belong to an isolated AWS account. Generally, you want to avoid human errors when a developer accidentally deletes some production resource instead of development one, and restrict production account to a limited number of "trusted" personnel only, while a wider set of developers (such as external consultants or summer trainees) can have access to the testing account.
This might sound trivial, but the opposite cases do happen from time to time, and it is important that the development team works in environments and insists on the maximal separation from day one.
Environment Names and Terraform Workspaces
Terraform Workspace is a way to create the same stack as usual, but isolated from "main" deployment, aka default workspace, somewhat resembling an Environment approach in a "terraform way".
$ terraform workspace new myusername
Created and switched to workspace "myusername"!A custom workspace is instrumental in various testing and debugging cases. Suppose you have a client that connects to your production environment, and s/he hits a problem. Surely, whenever possible, you simply want to reproduce the problem in the testing environment (and if that is possible, please go this way). But in a complex system, an error may be only reproducible on production data and under production load. It is seldomly possible to replicate to a testing environment all data and production load patterns across your system and all its Dependences, some of the latter belonging maybe to entirely different company). So you are opening production logs, but alas, they are insufficient and you can not find an exact reason; a natural way to proceed is to add more diagnostics or just isolating the calls made by a single client - it is not an easy task as production systems are typically overburdened by frequent messages from all over the world, so filtering the logs might be very challenging and also very slow.
The following approach probably will not help you with the bugs of performance kind, but allow you to peruse production setup for the diagnostics. See the ajacent blog post How to test a service under production load before going to production to peek into some load testing techniques.
Isolating your production debugging is then possible by creating a dedicated Workspace, the approach resembles the Canary Pattern:
- We modify the code we need to debug with more logging and diagnostics.
- We deploy our production Environment resources in a custom Terraform workspace. It will use all the Terraform variables for the production environment, yet the resource instances will be different; for instance, you will receive an API Gateway with a separate URL.
- We direct the traffic from the client who is having an error to that separate API Gateway and the call goes via the new resources and information is written in separate CloudWatch logs; therefore, the call is isolated, it is easier to locate the logs (as these are the only logs in your custom workspace), while other clients are not affected. When a fix is made, it can be also first tried in the custom workspace, so the only person who works against the separate URL is experiencing the changes.
- Once a fix is found, you can ensure that nothing else is broken using your normal quality assurance process and propagate the code to real testing and production environments. Do not forget to add a test for the freshly fixed regression.
To enable the use of workspaces and avoid clashes with other resource names from the same Environment but different workspace, it is, therefore, necessary to include workspace name as a part of the resource being created; for instance, preproduction environment can be set up by including in your main.tf or other Terraform file a snippet like
locals {
environment_name = terraform.workspace == "default" ? "preproduction" :
"preproduction-${terraform.workspace}"
}
# Resources always include the environment name
resource "aws_rds_cluster" "aurora_db" {
cluster_identifier = "${local.environment_name}-aurora"
...
}git branching model and CI/CD
Many people are familiar with git flow model and I am also keen to have a similar structure. If a project is simple and modularized, having new features developed in a feature-branch and merged in the main branch (we called ours development) might be sufficient.
We also control our Continuous Delivery using git branches. When we have development, preproduction, and production Environments, we also create the same-named branches. Merging into such a branch means that our Continuous Delivery pipeline will deploy the code in the respective environment automatically. To ensure that unverified code does not end up in Production, we make sure that:
- pull requests are the only way to amend the branches being deployed.
- we have configured Codeowners in GitHub, so while the entire company can have access to our repository and anyone can offer Pull requests, only maintainers of the project can approve it.
- once deploy to an environment completed, integration tests are started on that environment to verify that no regressions are created. In addition, I run integration tests also daily, as even if our code might not change, our Dependences may have new regressions and it is best to catch these early.
The easiest way to have a lightweight yet powerful CI/CD implementation is to utilize GitHub Workflows and actions. Various workflows can be triggered manually, upon pull request, by start or end of another workflow, and so on.
And of course, we always run a whole set of automated tests in development and preproduction testing Environments, and code must be promoted from one to another in order. Definition of done includes mandatory test coverage for new code created, and these tests must be supplied together with the new code, not much later.
Reusable Terraform code and Environments
To keep things in sync between environments, we utilize the modularized approach. We utilize the following git repository folder structure:
repository root/
├─ .github/
│ ├─ ... CI/CD setup files and folders...
├─ src/
│ ├─ ... files and folders for your business logic code,
completely deployed by Terraform and CI/CD...
├─ terraform/
│ ├─ development/
│ │ ├─ main.tf
│ ├─ preproduction/
│ │ ├─ main.tf
│ ├─ production/
│ │ ├─ main.tf
│ ├─ modules/
│ │ ├─ infrastructure-main/
│ │ │ ├─ variables.tf
│ │ │ ├─ main.tf
│ │ │ ├─ outputs.tf
│ │ ├─ some-submodule/
│ │ │ ├─ ... submodule files ...
├─ tests/
│ ├─ ... files for jest tests ...
├─ README.mdWe create a "main" Terraform Module under terraform/modules/infrastructure-main that takes environment name as one of its parameters parameter and creates all AWS resources.
Then, an environment-specific folder /terraform/<env>. contains only the main.tf file that configures the Terraform backend for the environment and has just one single call to the Module providing environment name and environment-specific configuration. Therefore, running terraform apply in /terraform/preproduction/ will create the Preproduction Environment.
README.md of course tells a developer to start looking from terraform/modules/infrastructure-main.
Ways of working are important
Any however well-thought technical system is not functional if a team lacks "soft skills" and ways to establish a safe, productive, and frictionless working environment in an organization. It is a major topic indeed, but here I just refer to some of my favorite texts:
- Things I believe — a collection of practical advice from a software developer.
- End-to-end DevOps: Lessons learned and why it's essential — an essay on how to create a cross-company open DevOps culture.
- 97 Things Every Software Architect Should Know: Collective Wisdom from the Experts — lots of essays about how to deal with architects' daily work challenges.
 Askar IbragimovCloud Architect and Senior Developer
Askar IbragimovCloud Architect and Senior Developer





